

2022年1月6日
Continuous Integration
UIビルドのためのHarness CI Enterpriseの活用
CIEパイプラインの作成方法(および独自のパイプラインの作成方法)と、キャッシュ戦略について説明します。
この記事では、Harness CI Enterprise (CIE) Pipelineの作成方法と、それを使ってUI Buildのための独自のパイプラインを作成する方法を説明します。また、より高速なジョブ実行を実現するために使用するキャッシュ戦略についても説明します。
CIとは?
Harness CIEを始める前に、CIとは何かを理解しておきましょう。
Continuous Integration(CI)とは、複数の貢献者によるコード変更を1つのソフトウェアプロジェクトに統合することを自動化することです。統合プロセスは、スクリプトとプロセスを必要に応じて頻繁に使ういくつかの特定のツールによって自動化できます。これは、新しいコードの互換性が自動的にテストされていることを意味します。さらに、これは、統合エラーが早期に発見されることをサポートします。さらに、ユニットテストやシステムレベルのテストは、開発者が介入することなく、自動的に実行されます。詳細については、「Continuous Integrationとは」の記事をご覧ください。
なぜHarness CIEなのか?
CIに関しては、多くのツールが利用可能です。しか��し、これらのツールは多くの手動スクリプトを必要とし、CIとCDの間に最小限の統合しか存在しないことが大きな欠点です。CI分野におけるこれらのツールの代表例として、Jenkinsがあります。
Harnessは、ビルドのトリガーとなったコード変更の品質を確認するために必要なテストのみを実行する機能や、テスト時間を大幅に短縮するTest Intelligenceなど、優れた機能を提供しています。
Harnessでは、CI Buildジョブを実行するためのBuildファームとしてKubernetesを使っています。Kubernetesでは、パイプラインのステップはコンテナーで実行されます。コンテナーはホストOSの軽量な抽象化であり、コードや依存関係をステップとは別にパッケージ化することができます。さらに、全てのステップがコンテナーで実行され、プラグインも独自のコンテナーを持っているため、依存関係を心配する必要はありません。
Harness CIEは、ネストされたステップを持つPipelineのグラフィカルな表現も提供します。UIから直接ビルドすることも、必要に応じてYAMLエディタを使用することもできます。YAMLエディタはIDEと同様の機能を持ち、コードとして簡単に設定することができます。
UIビルド用パイプラインを構築するためにHarness CIEを活用する方法
4つの簡単なステップでCIEパイプラインを作成し、実行できます。
- 新規にPipelineを作成し、Pipelineステージを作成しながらコードベースをクローン
- ビルドファームのインフラを定義
- 実行ステップを追加
- パイプラインを実行
CIモジュールの「Create a Pipeline」でPipeline Studioに移動し、ステージを追加します。さまざまなCI Stepを組み合わせて、複数のStageを作成できます。各Stageには、コードをビルド、プッシュ、テストするためのStepが含まれています。
そのため、PRチェックのためのPipeline内に複数のステージを並行して作るか、PRチェックごとに個別のPipelineを作るかのどちらかを選びます。
コードベースのクローニングを行うには、Harness Delegateをインストールすることが大前提となります。DelegateはHarness CIE操作の全てを担当し、Harness Managerと全てのコードリポジトリー、アーティファクト、インフラ、クラウドプロバイダーを接続します。
コードベースのクローンを作成するための主なアクションアイテムは以下の通りです。
- GitHub Connectorの作成
- コードベースがあるGitHubリポジトリーにHarnessを接続
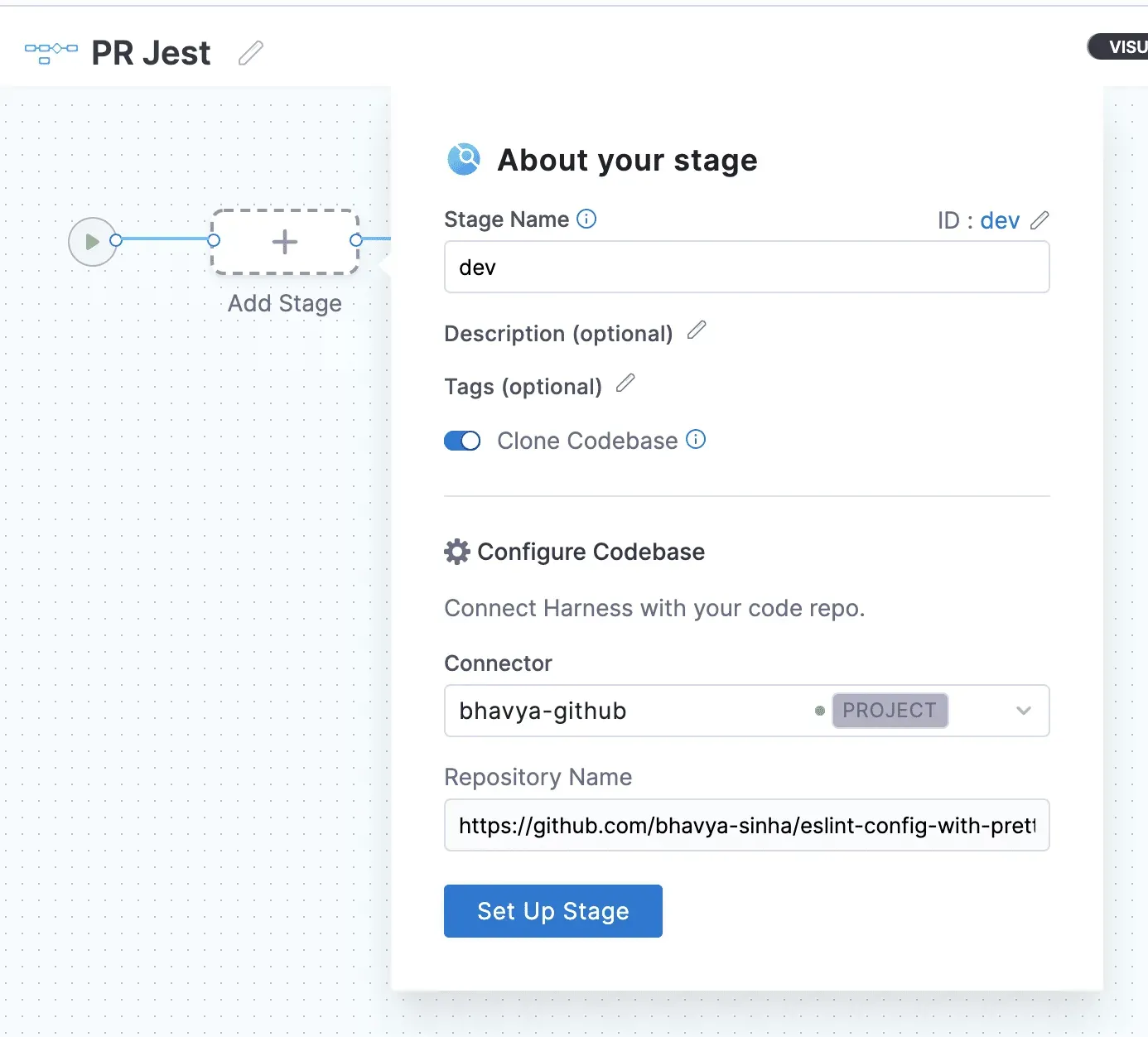
ビルドファームのインフラを定義するために、Kubernetes Clusterを選択する必要があります(またはKubernetes Connectorを作成します)。このConnectorは、ビルドファームとして使うクラスターにHarnessを接続するものです。
Namespaceには、使用するKubernetesの名前空間を入力します。
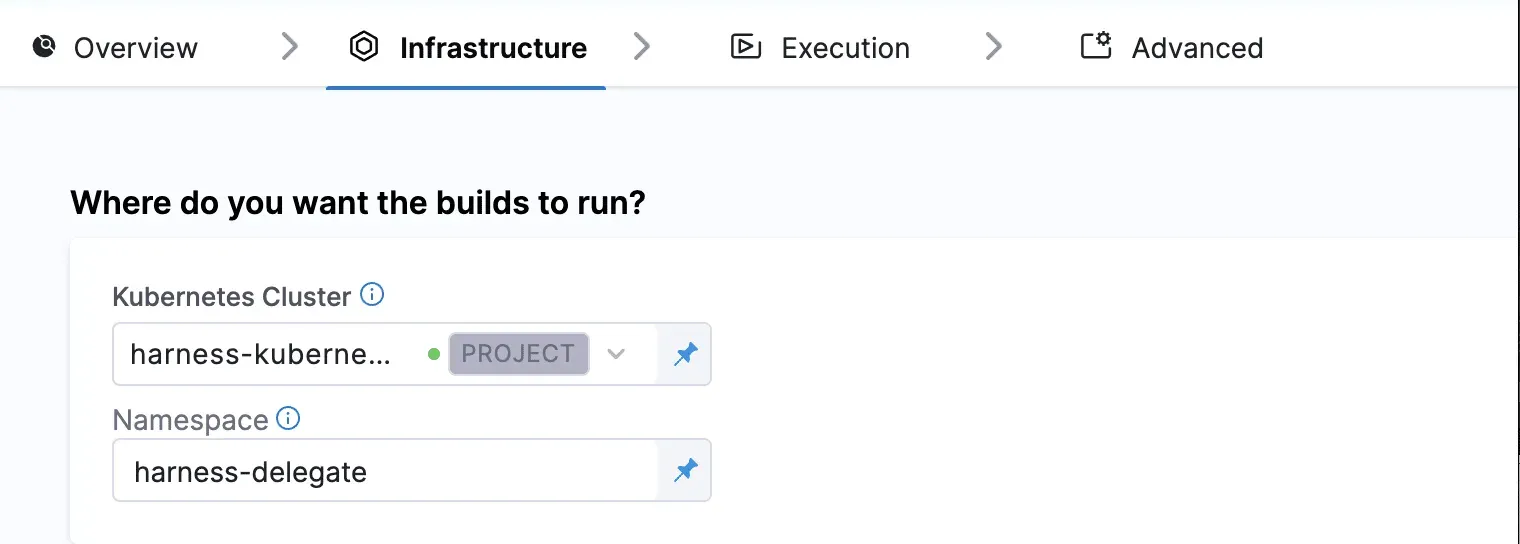
Pipeline Execution Step(パイプライン実行ステップ)は、あるアクションを実行するために使用される一連のコマンドと定義されます。たとえば、Run and Run Tests ステップは、コンテナーイメージ上で1つまたは複数のコマンドを実行します。コマンドは、gitリポジトリーのルートディレクトリー内で実行されます。パイプラインステージの全ステップが、Gitリポジトリーのルート(ワークスペースとも呼ばれる)を共有します。Harness CIでは、ステップを追加したり、ステップを組み合わせたりして、要件に応じたPipelineを作成できます。
Caching Strategy
UI Build PRチェックのPipelineを設定する際には、Harnessのキャッシングメカニズムを使用します。キャッシュは、以前のジョブからコストが大きいフェッチ操作のデータを再利用することで、より高速なジョブ実行を保証します。
Harness CIE Pipelineでは、Save Cache to S3ステップを使いキャッシュをAmazon Simple Storage Service (S3) バケットに1ステージで保存し、Restore Cache from S3ステップで同じステージまたは別のステージで復元することが可能です。
また、Harnessには、GCSへのキャッシュの保存とGCSからのキャッシュの復元を行うステップが用意されています。
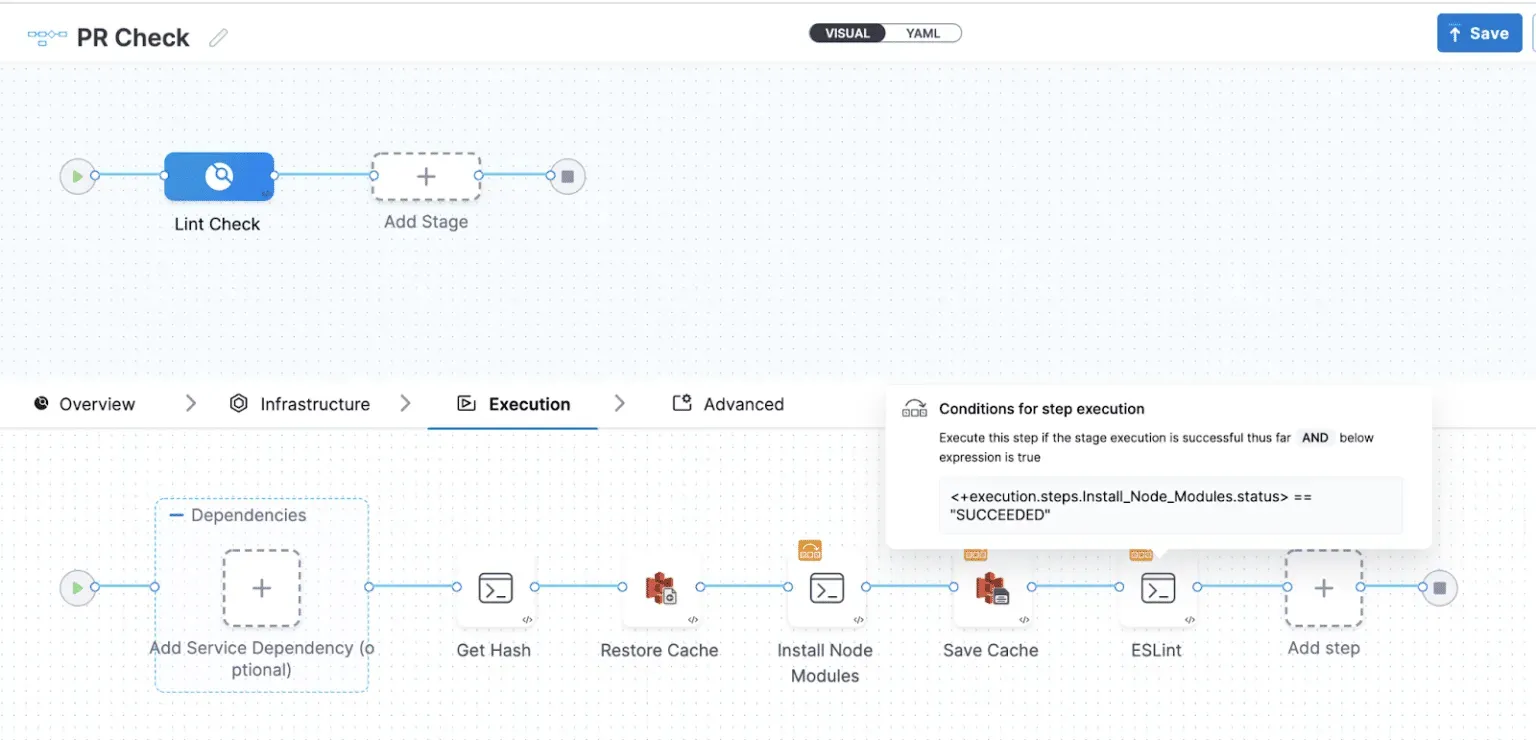
PR check Pipelineの構成で使う実行ステップは、以下の順序で実行されます。
1- ハッシュを取得する。ハッシュの取得には、カスタムスクリプトを追加できるRun executionステップを使います。この例では、docker-hubレジストリーからnode:16イメージを使用して、ステップ用のカスタムスクリプトを実行しています。`openssl sha1 yarn.lock | cut -c 22-` を使って yarn のロックハッシュを取得し、出力変数を使ってそのハッシュを公開します。これにより、キャッシュを保存できます。
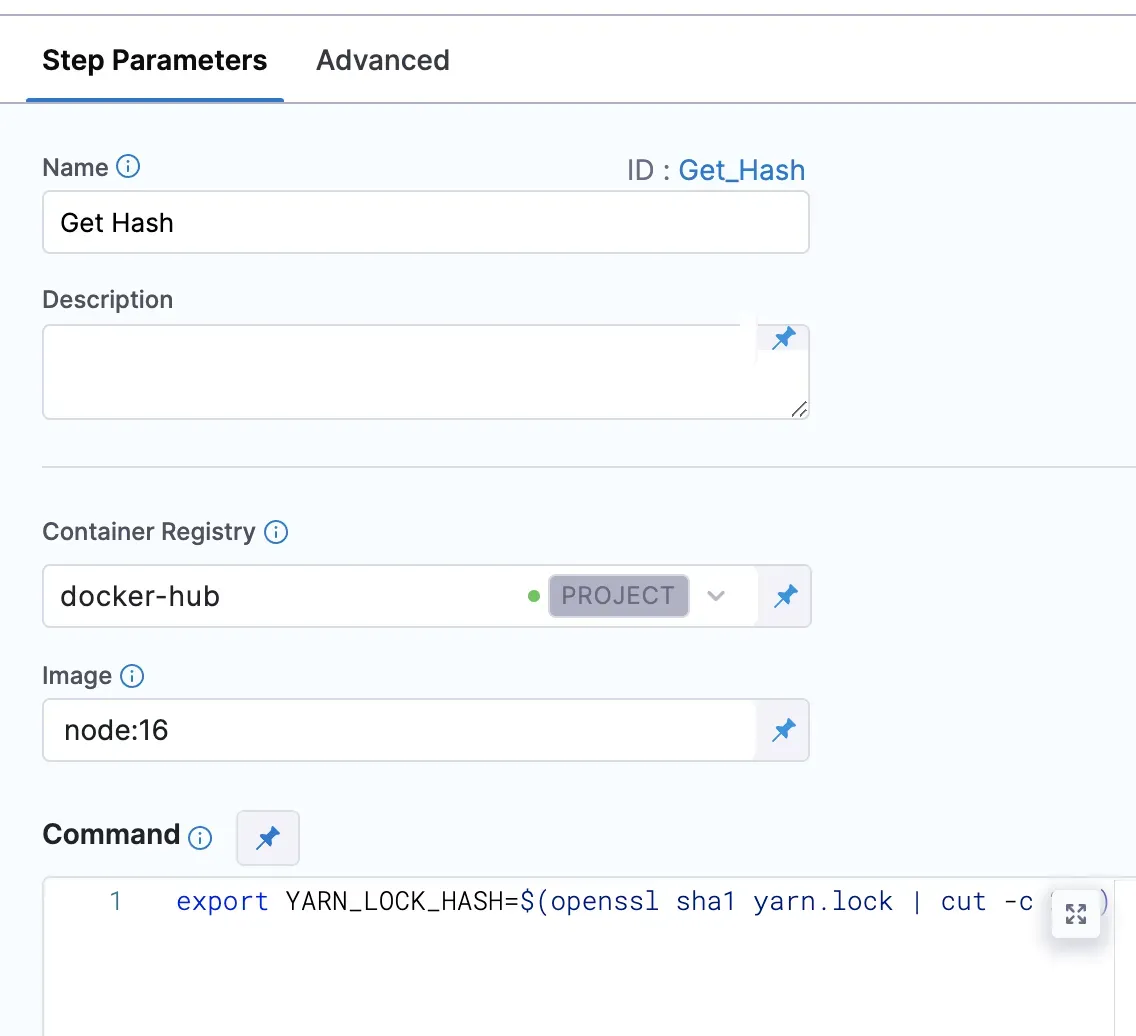
この例では、キャッシュを保存するために次のキーを使用しています:nodeModules-${outputVariable}、ここでoutputVariableは、前のステップでYARN_LOCK_HASHを公開するために使用した変数です。
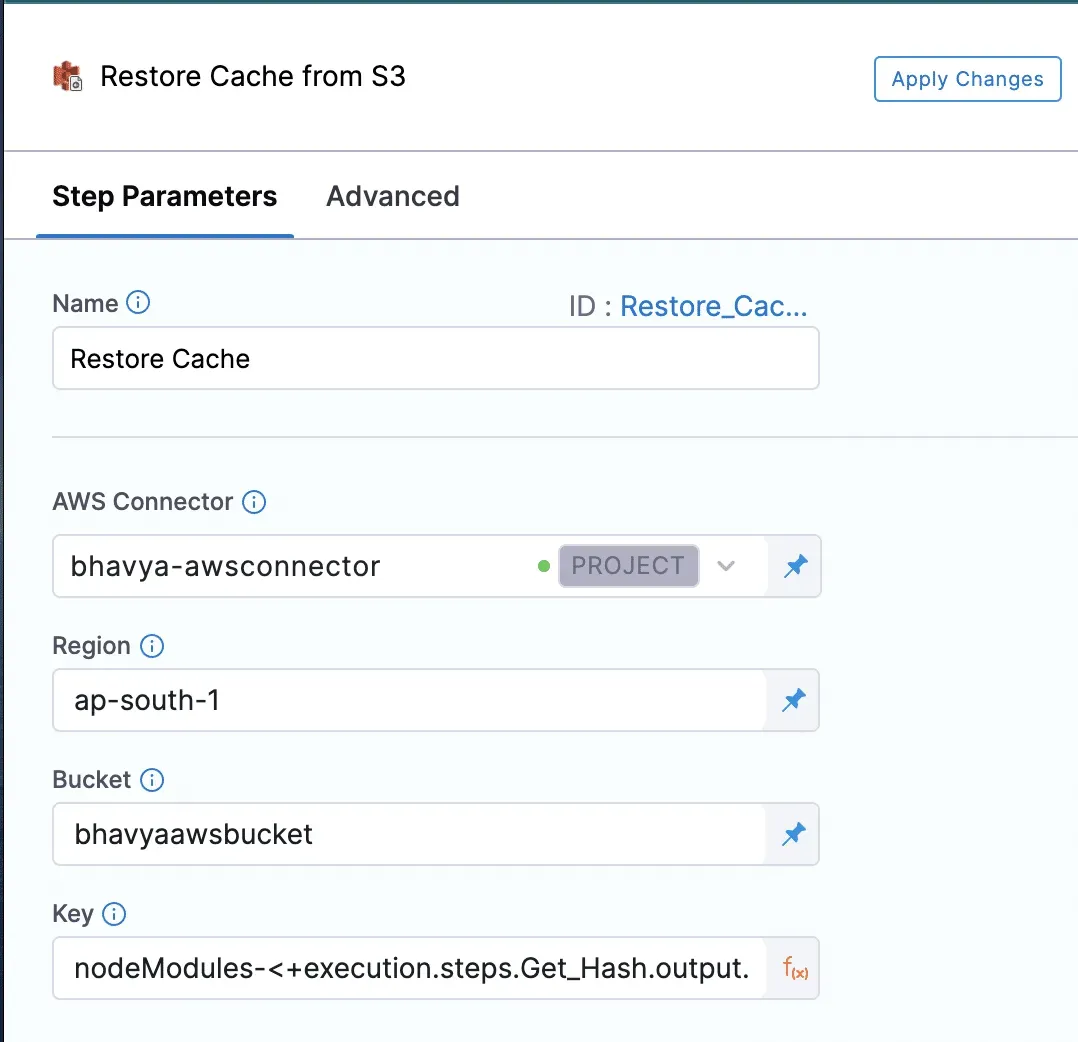
2- キャッシュを復元する。次のステップは、キャッシュのリストアです。このステップは、キャッシュの保存やノードモジュールのインストールの前に追加され、キャッシュがすでに存在するかどうかを確認し、そこから復元するためのものです。これには、キャッシュを保存するためのAmazon S3またはGCSバケットが必要なだけです。キャッシュをキーに保存します。
この例では、キャッシュを保存するために次のキーを使用しています:nodeModules-${outputVariable}、ここでoutputVariableは、前のステップでYARN_LOCK_HASHを公開するために使用した変数です。
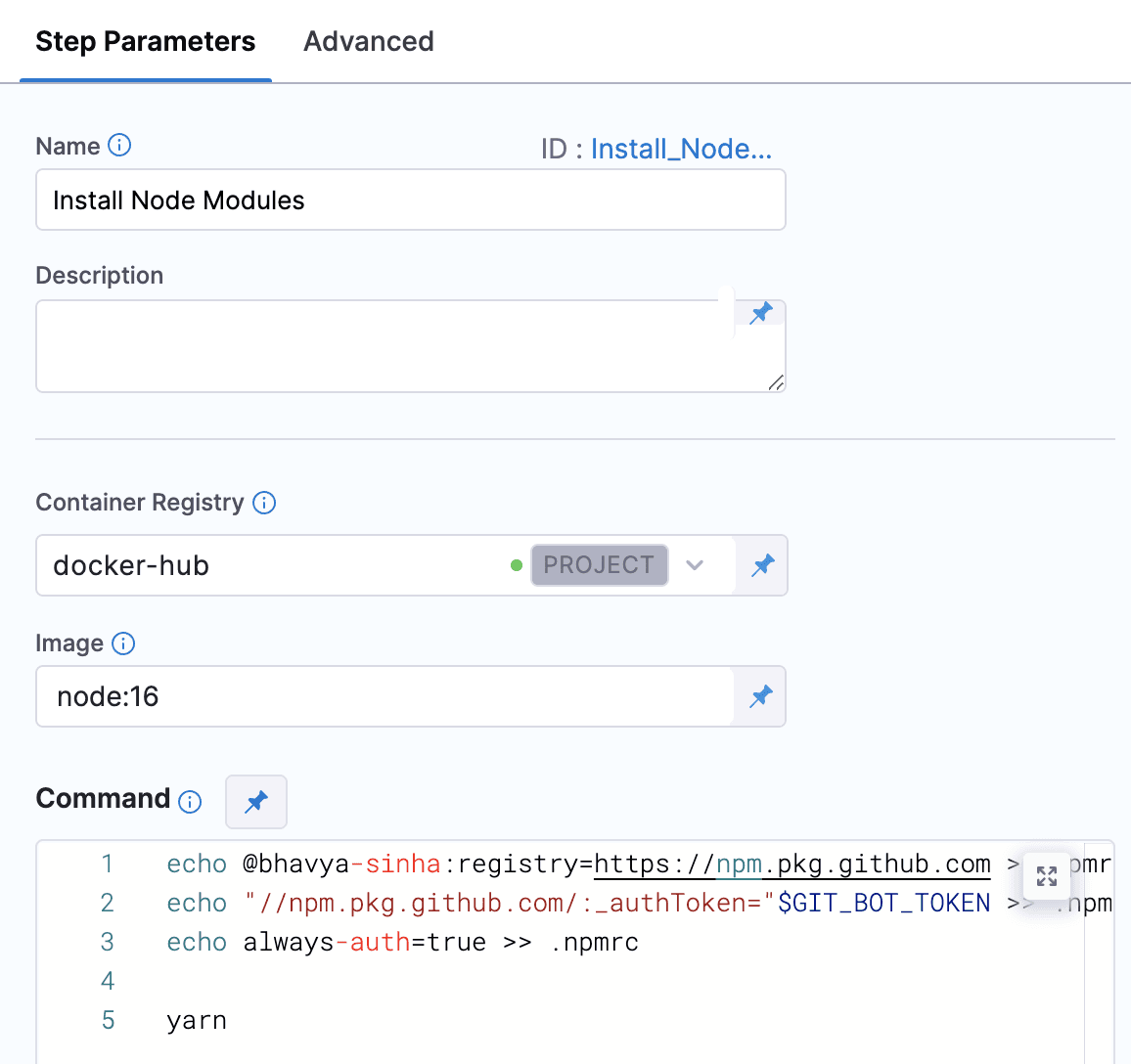
3- ノードモジュールのインストール。次のステップは、nodeモジュールのインストールです。Harness CIEをnpmレジストリに接続するためのスクリプトを追加します。そして、nodeモジュールをインストールするためのyarnスクリプトを追加します。
4- キャッシュを保存する。ノードモジュールをインストールした後、ファイル/フォルダーをキャッシュに保存する必要があります。これは、次の実行でキャッシュからリストアできることを意味します。Save Cacheステップを設定する際に、キャッシュを保存するAmazon S3/GCSバケット、リージョン、キーがRestore Cacheステップのものと同じであることを確認する必要があります。ソースパスは、添付画像にあるように、キャッシュするファイルやフォルダのリストです。この例では、node_modulesです。
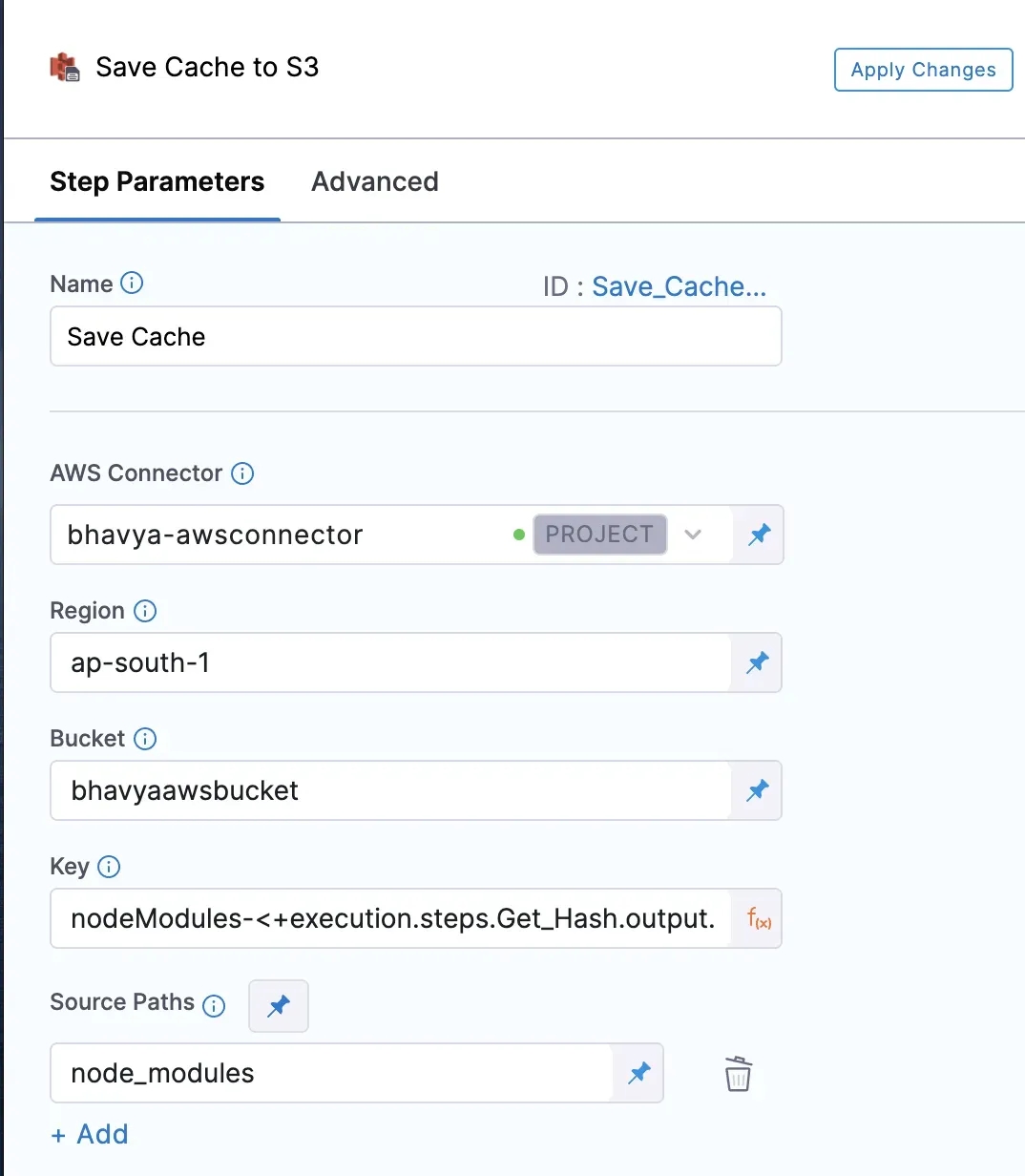
5- 実行ステップでビルドを実行する。PRチェックのためのUIビルドを構成する最後の実行ステップは、Runステップを追加することです。ここでは、ES Lint、Prettier、Jestなど、特定のPR Checkを実行するためのカスタムスクリプトを追加できます。今回もHarness CIEをnpmレジストリに接続するスクリプトと、yarn lintを使用してESLintジョブを実行するスクリプトを追加しています。
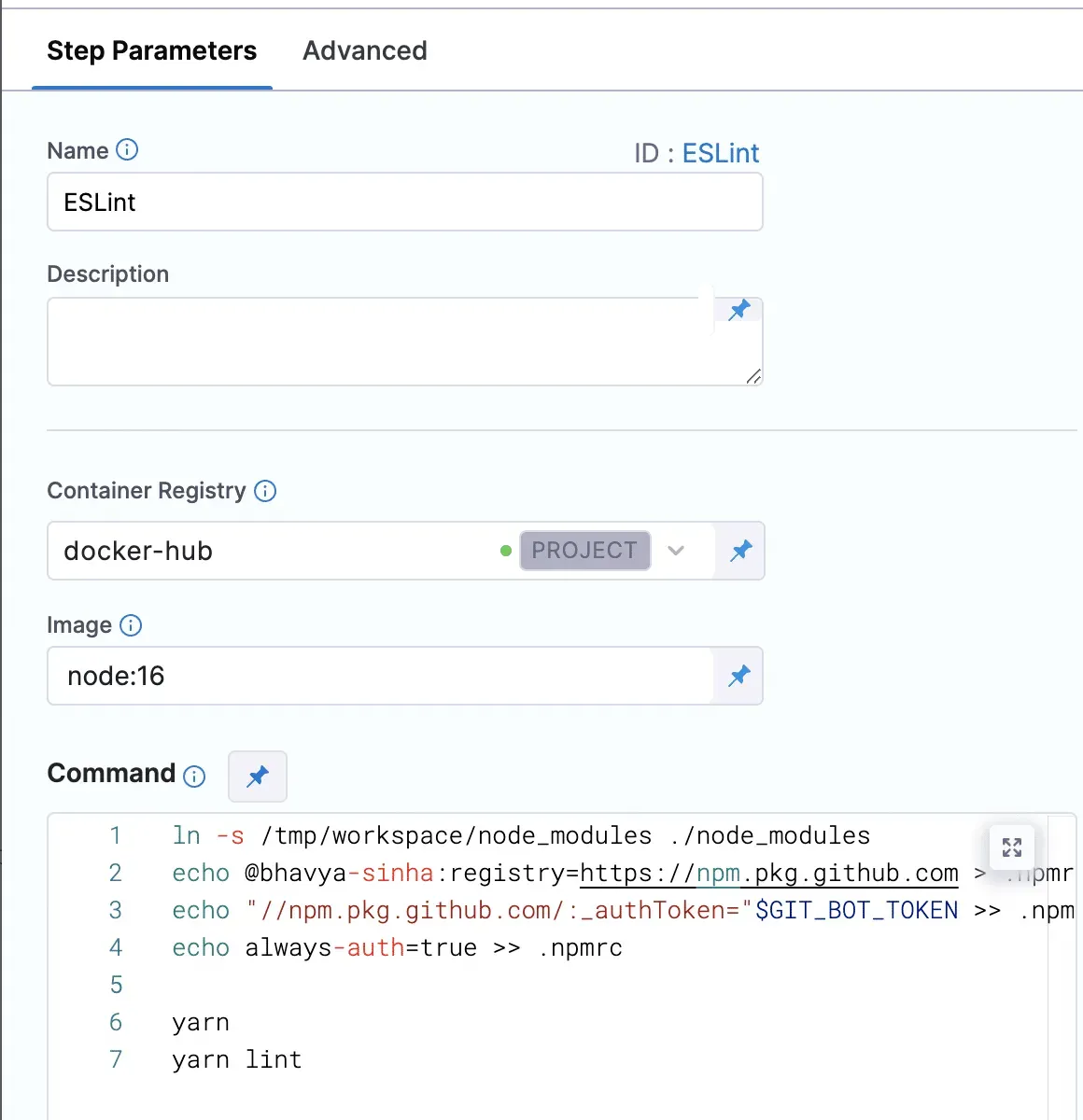
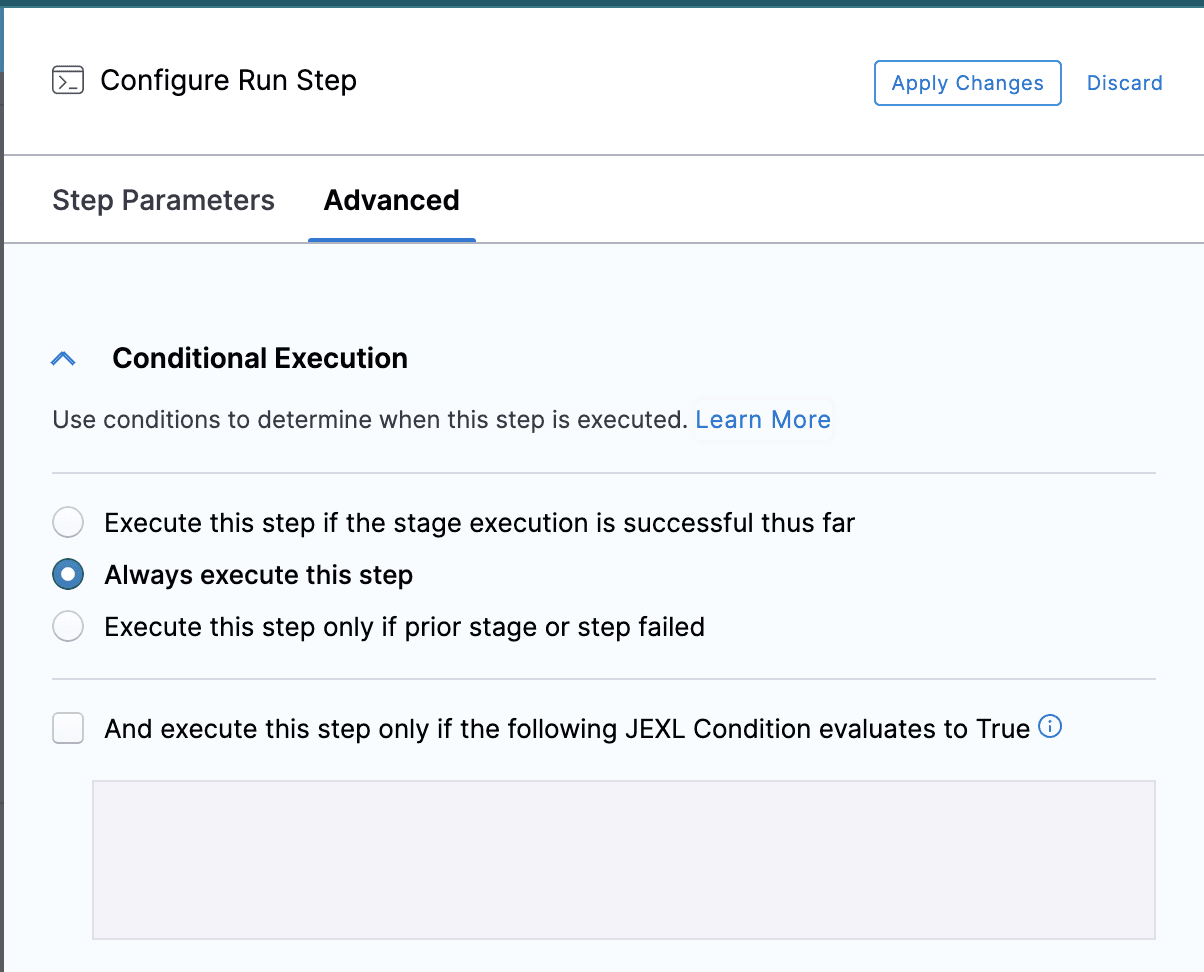
なお、ステップの設定中、Restore from Cacheのステップに失敗しても、パイプラインは失敗しないようにします。これはHarness Pipelineのデフォルトの動作です。
そのためには、Install node modulesステップ(Advancedタブ)でAlways execute this stepにチェックを入れ、Install node modulesの次のステップで<+execution.steps.Install_Node_Modules.status> == “SUCCEEDED” の条件を追加します(下図参照)。
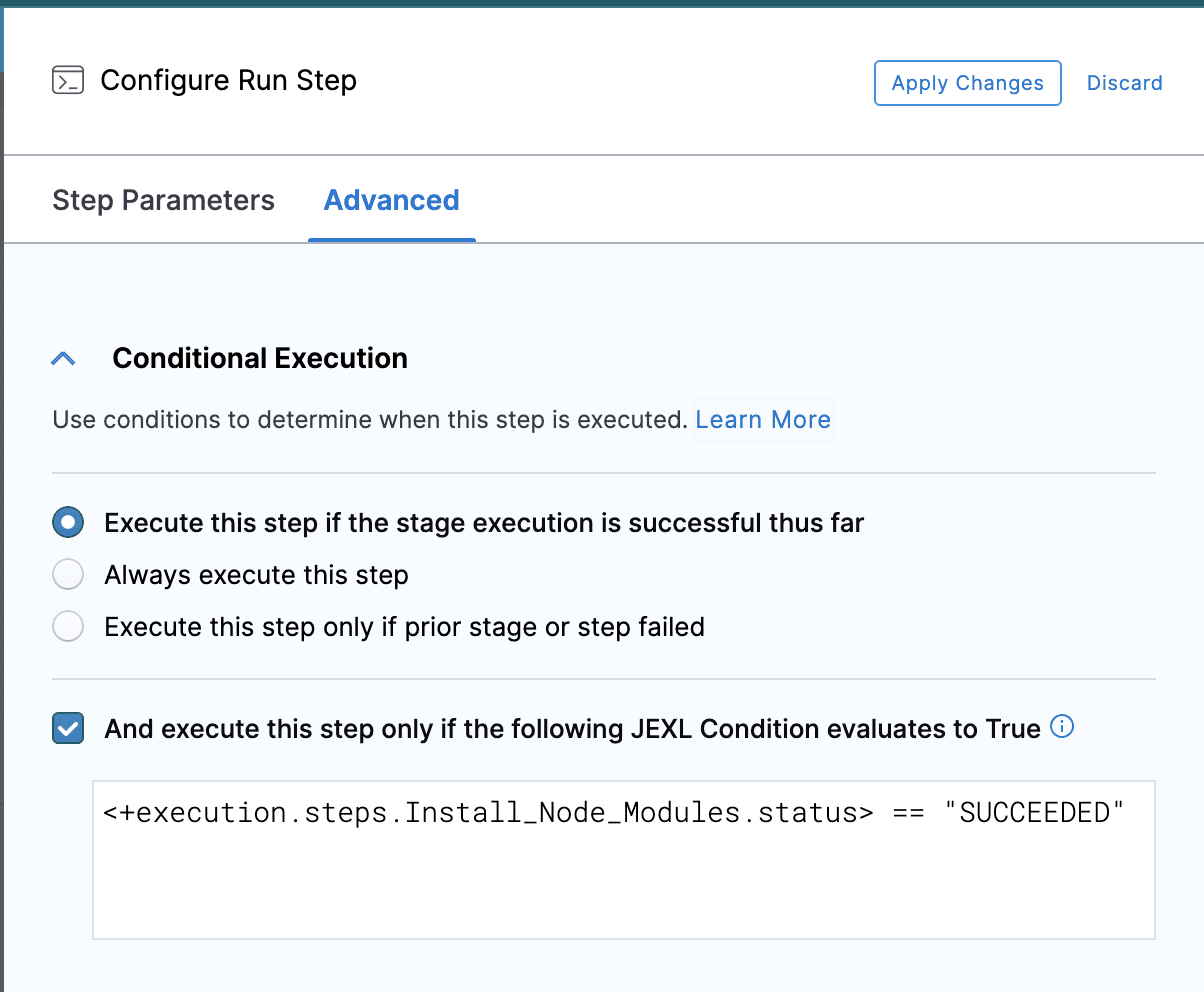
パイプラインの実行を確認する
設定部分が終わったら、あとはPipelineを保存して実行するだけです。実行結果は、実行ステージの詳細やコンソールビューで確認できます。
パフォーマンスに関する事項
これまでのセクションで、キャッシュがパイプラインの実行性能を向上させることを説明しました。以下の例を使って、同じことを理解してみましょう。
シナリオ1
このシナリオでは、キャッシュからファイルを復元せず、代わりにノードモジュール全体をインストールします。この場合、パイプラインの実行に5分2秒の時間を要します。

シナリオ2
このシナリオでは、バケットにキャッシュが存在し、キャッシュからノードモジュールをリストアしました。この実行には1分25秒しかかかりませんでした。

これは、非常に単純なパイプラインの例に過ぎません。しかし、多くのステージやステップを持つパイプラインの場合、キャッシュあり戦略とキャッシュなし戦略の差は明らかに大きくなるでしょう。
Harnessのプライベートリポジトリーで実行されるジョブにこのキャッシュ戦略を適用することで、UIビルドにかかる時間を約10分短縮することができました。これは大きな成功を示す数値だと思います。
また、キャッシュ戦略により、ネットワーク帯域幅も節約できました。Harnessでは、毎日何百ものCIEジョブを実行しています。そのため、各ジョブの平均サイズが1GBの圧縮ノードモジュールをネットワーク経由でダウンロードしなければならないとしたら、このタスクに消費されるネットワーク帯域幅がどんなに大きいか、想像し�てみてください。さらに、通常、ノードモジュールは更新されません。つまり、キャッシュあり戦略によってネットワーク帯域をさらに節約できるのです。
結論
この記事を読んで、UIビルドのためにHarnessパイプラインがどのように作成されるかを理解していただき、ありがとうございました。これであなた自身のHarness CIE Pipelineを設定できるようになることを大いに期待して、この記事を終わります。
CIについてもっと知りたい方は、JenkinsからHarness CIEに移行する方法を読んで、ぜひご自身で試してみてください。Harness CIEについてもっと知りたい方はHarness CIE docsをご覧ください!
Harness Service Reliability Managementの詳細や導入にご興味がおありですか?詳しくはこちらをご覧ください。
この記事はHarness社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。