

2022年2月8日
Continuous Delivery
Harness Kubernetesのデプロイメントで孤立したリソースを自動プルーンする
自動プルーニング機能は、マニフェストから削除されたものの、まだクラスターに残っているリソースを処理��します。クリーンアップの手間を省くことができます。
デプロイメント環境においてぶら下がったリソースは誰も望んでいません。ごちゃごちゃして、不必要にリソースを消費してしまうからです。特に、複数の管理者/開発者が環境を管理していて、所有者とナレッジが分散している場合は、苦痛を伴います。 さらに、カナリアやブルーグリーンのような高度なデプロイメント戦略を使用する場合、特にリリースのロールバックを処理する場合、これらのリソースの追跡はさらに複雑になります。このような状況を救うために、私たちHarnessは自動プルーニングという制御されたカスタム可能なソリューションを提供します。これにより、安心してより重要なタスクに集中することができます。
期待が高まってきましたか?私たち�の取り組みやデザインについて、もっと知りたい方は続きをどうぞ。
Harnessを使ったk8sデプロイメントの日常
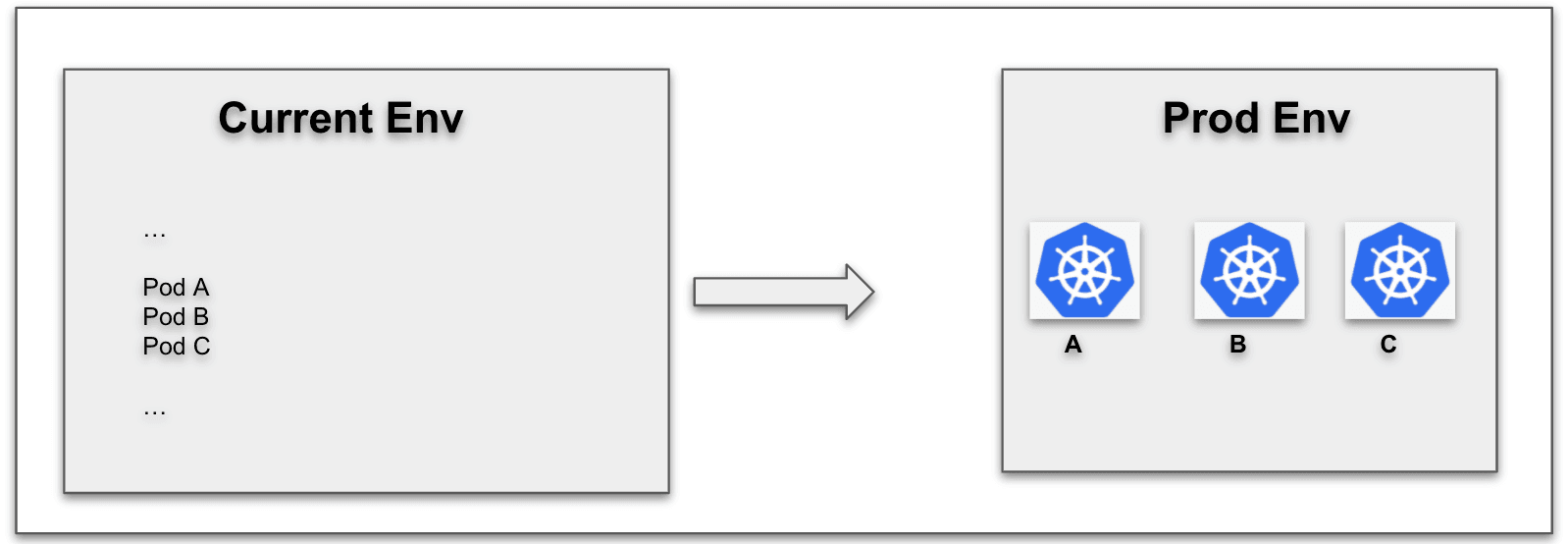
リリースR1 - 成功するデプロイメント
プルーニングについて説明する前に、Harnessを使った通常のk8sのデプロイメントについて理解しておく必要があります。ローリング、カナリア、ブルーグリーンなど、複数のデプロイメント戦略をサポートしています。さらに、複数のマニフェストソースから選択することができます。簡単なローリングデプロイの例で、さらに詳しく見ていきましょう。
まず、Serviceを作成する必要があります。次に、それぞれのコネクター情報を入力して、デプロイするマニフェストソースとアーティファクトを選択します。
次に、Infrastructure Definitionセクションで、クラスターやネームスペースなど、対象となるインフラストラクチャーを定義します。
最後に、前のステップで作成したServiceとInfrastructure Definitionを使用してローリングデプロイメント戦略でワークフローを作成し、ワークフローを実行して環境にデプロイします。
これで完了です。継続的デリバリーに幸あれ!
孤立したリソース問題
組織レベルでは、これらのデプロイメントの頻度と複雑さは高いです。つまり、異なるリリースをロールアウトまたはテストするために、Kubernetesクラスター上で異なる環境をセットアップする必要があります。そのため、チームはマニフェストを頻繁に更新しなければなりません。これらのことは全て、さまざまな更新�の際にマニフェストから削除されたものの、不必要にクラスター上にある未所有または未追跡のリソースの行に追加されます。これらのリソースは追跡されていないだけでなく、予期しない動作を引き起こす可能性があります。
あるお客様はこのようなシナリオに直面しました。クラスターに不要なイングレスが残っていて、それが不正なルーティングを引き起こしていたのです。このようなリソースを手動で管理し、クリーンアップすることは、多くのお客様にとって常に問題となっています。
そこで、これらの問題に対処し、Kubernetesの使い勝手を向上させるために、私たちは自動プルーニング機能をロールアウトしました。
問題の分解
環境内のぶら下がりリソースという問題に戻ります。さまざまな側面を以下のように細分化しました。
- プルーニングのためのフィルター条件を決定し、異なる戦略でロールバックを処理する
- どこで、何を、どのように
- ストレージとセキュリティーへの配慮
次のセクションでは、上記の各側面を解決するための設計について説明します。
プルーニングのためのフィルター条件を決定し、異なる戦略でロールバックに対応する
ローリングデプロイメントケースA
たとえば、最初のリリース(R1)で、マニフェスト(M1)から複数のリソース(A、B、C)をデプロイしたとします。
次に、2番目のリリース(R2)で、マニフェストをバージョンM2に更新し、リソース A、B、およびDを含むようにし、それをデプロイしたとします。
これで本番環境にはリソースA、B、C、およびDがありますが、Cは不要なリソースです。
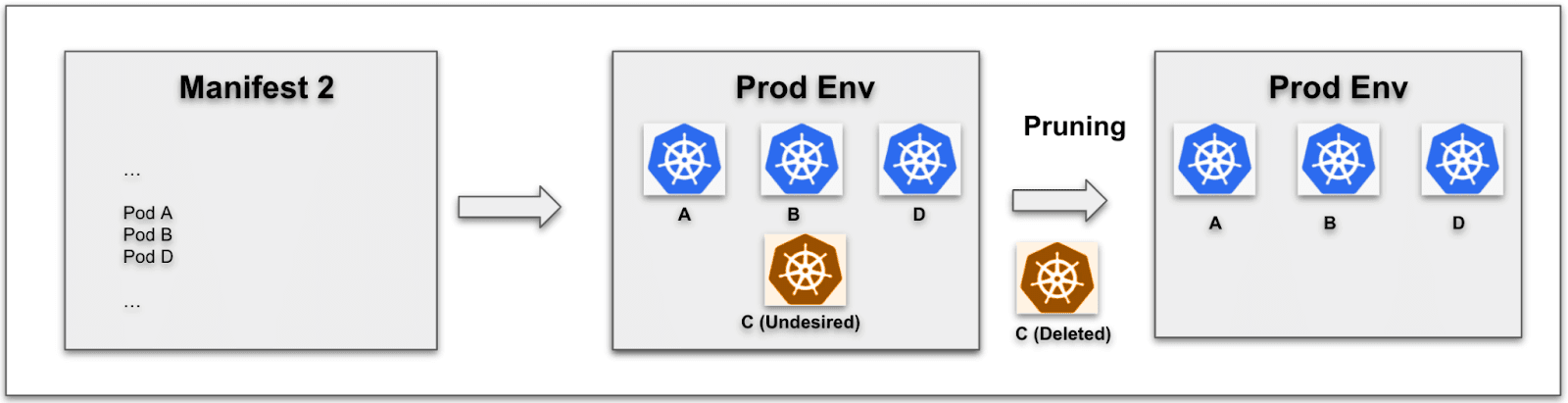
リリースR2 ケースA - デプロイメント成功後の自動プルーニング
ローリングデプロイメントケースB
上記のシナリオを変更すると、リリースR2が失敗し、本番環境をリリースR1のデプロイ後の状態にロールバックする必要があるとします。この場合、新しいリリースR2の展開中に削除されたリソース(この例では、リソースC)の再作成を処理する必要があります。
ここでもう1つ言及すべき点は、ロールバックによって、最後に成功したデプロイの後と同じ環境を作るということです。つまり、現在と最後に成功したデプロイメントの間に、複数の失敗したリリースがデプロイされたとします。ロールバックの後、環境は最後に成功したデプロイメントの後の状態に復元されます。
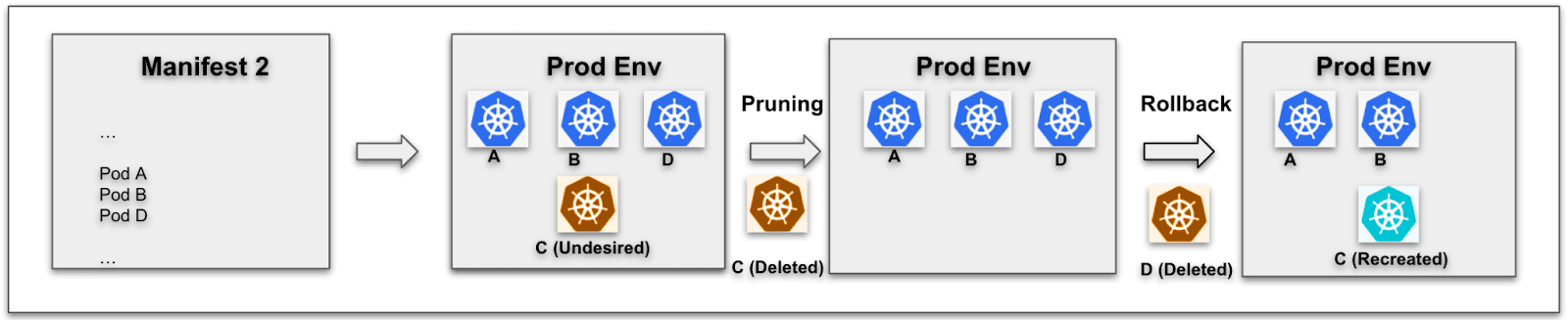
リリースR2 ケースB - デプロイメント失敗後のロールバック
ブルーグリーンデプロイメント
ブルーグリーン戦略は少し違います。そのため、自動プルーニングを実装するために異なる処理が必要となります。シナリオの例は次のようになります。
既に2つのリリース、R1とR2を連続してデプロイしているとします。R1にはマニフェストM1で定義されたリソースA、B、およびCが含まれ、R2にはマニフェストM2で定義されたリソースA、B、およびDが含まれます。現在、リリースR1はstage setupに関連付けられ、リリースR2はprodsetupに関連付けられています。その結果、クラスターにはリソースA、B、C、およびDが含まれます。
次に、マニフェストをM3に更新し、リソースA、B、およびEを含み、この新しいリリースR3をprod setupとしてデプロイしたいと思います。デプロイが完了すると、リリースR2はstage setupに、R3はprodに関連付けられます。今、あなたのクラスターには、リソースA、B、C、D、およびEがまとめて含まれています。
上記のシナリオでは、リソースCが不要になります。ここから言えるのは、以前のstage setupに関連付けられたリリースに特に存在するリソースは、プルーン候補になるということです。
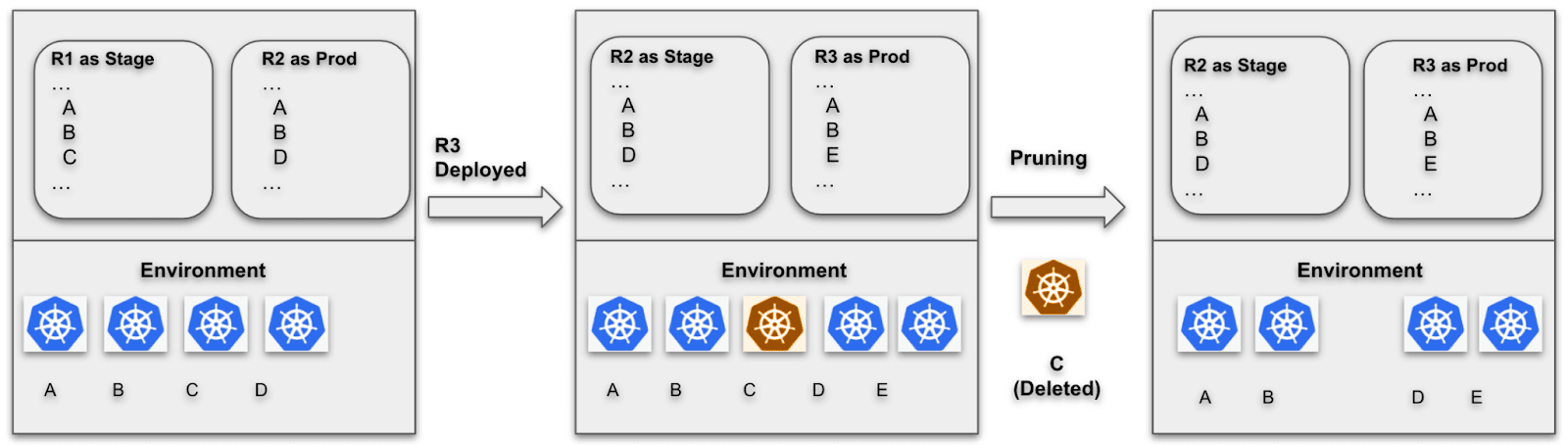
ブルーグリーンデプロイメント後の自動プルーニング
どこで、何を、どのように
Harnessは、リリース履歴をクラスター上のConfigMap Release Historyに保存します。これには、ワークロード、CRD、およびバージョン情報についてのいくつかのメタデータが含まれています。どの時点でも、2つのデプロイメントの状態(Currentと最後のSuccessfulのデプロイメント)が含まれています。
プルーン目的でこのConfigMapを使用します。新しいマニフェストM_NEWでデプロイメントが開始されると、最後に成功したリリースでデプロイされたリソースと M_NEWにあるリソースを比較します。最後に成功したリリースにあり、現在のリリースに存在しないリソースは、デプロイメントの後にプルーニングされます。
ロールバックでの再作成。また、リソースのレンダリングされたYAMLをConfigMapに文字列として保存します。これは、ロールバックが発生した場合に、現在のデプロイメントステップで既にプルーニングされたリソースをそのYAMLから再作成する方法です。
カスタマイズ性。 ある特定のリソースがプルーニングに含まれないようにしたいシナリオがあるかもしれません。これを解決するために、リソースYAMLに含めることができるアノテーション、harness.io/skipPruning: trueを提供します。
介入に対応する。 環境に複数の介入があって自動プルーニングが失敗する可能性があります。例えば、現在のデプロイメントでプルーニングするはずだったリソースを手動で削除した場合や、到達できないクラスターがある場合などです。このような場合でも、パイプラインはその場で失敗させず、さらなるステップの実行を継続させます。
ストレージとセキュリティー
マニフェストサイズは通常、ConfigMapストレージの制限値である1MBよりも大きくなります。そのため、ReleaseHistory ConfigMapに保存する前に、BEST_COMPRESSION設定で広く受け入れられているJava deflatorを使用して、レンダリングマニフェストを圧縮およびエンコードしています。これにより、1MBを超えるマニフェストの�保存に関する問題が解決されました。
もう1つの問題は、お客様がCRDを公開したくないということでした。そのため、CRDのレンダリングされたYAMLをConfigMapではなくKubernetes Secretsとして保存しています。
結論
多くのお客様は、既に自動プルーニング機能を活用し、環境をきれいに保つための余分な労力を省いています。従って、これらのリソースを追跡しクリーンアップするための手作業が省かれています。さらに、マニフェストで設定を最新に保つことができ、孤立したリソースによる予期せぬ動作の心配もありません。
自動プルーニングを活用するために、お客様はもはや基本的なロールアウト戦略でのみ利用可能なネイティブHelmを使用することに制限されることはありません。その代わりに、Kubernetesのデプロイメントを選択し、カナリアやブルーグリーンなどの高度なロールアウト戦略や、複数のマニフェストストアのオプションと一緒に使用することができるようになりました。
Harnessを使ってKubernetesの使い勝手を向上させるという記事を楽しんでいただけたでしょうか。さあ、こうしてはいられません。Captain Canaryと一緒にHarnessの旅を始めましょう。
もし、まだ時間が必要であれば、さらに読み進めて情報を得てください。カナリアとブルーグリーンのリリース戦略については何度か触れているので、これらの概念をもっとよく理解してみてはいかがでしょうか?こちらの記事をどうぞ。デプロイメント戦略入門。ブルーグリーン、カナリアなど
この記事はHarness社のウェブサイトで公開されているものをDigital Stacksが日本語に訳したものです。無断複製を禁じます。原文はこちらです。